I’m attending the https://linux.conf.au/ conference online this weekend, which is always a good opportunity for some sideline hacking.
I found something boneheaded doing that today.
There have been a few times while inventing the OpenHMD Rift driver where I’ve noticed something strange and followed the thread until it made sense. Sometimes that leads to improvements in the driver, sometimes not.
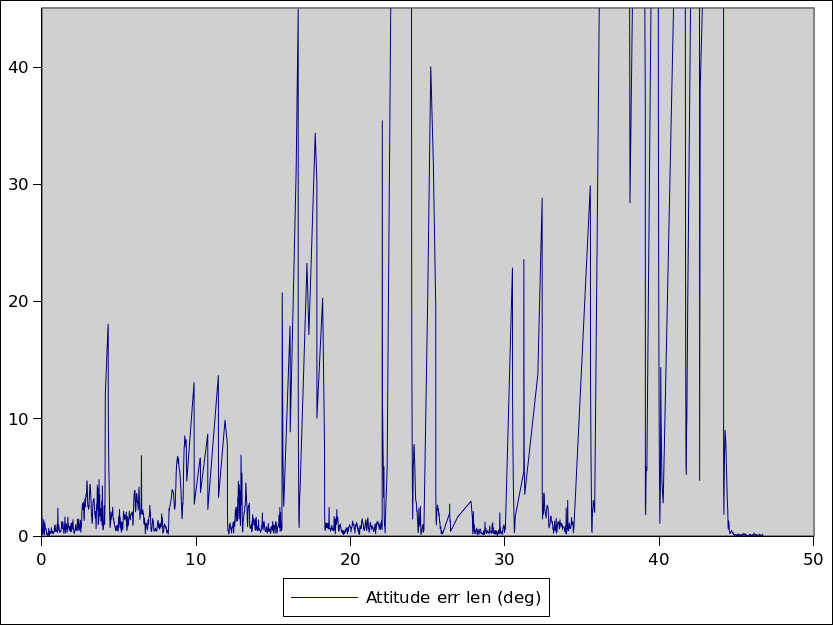
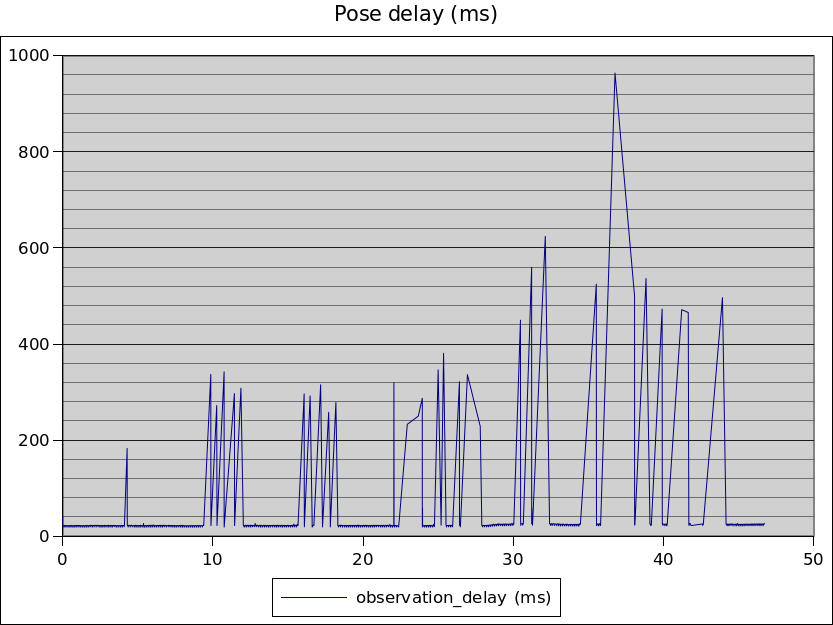
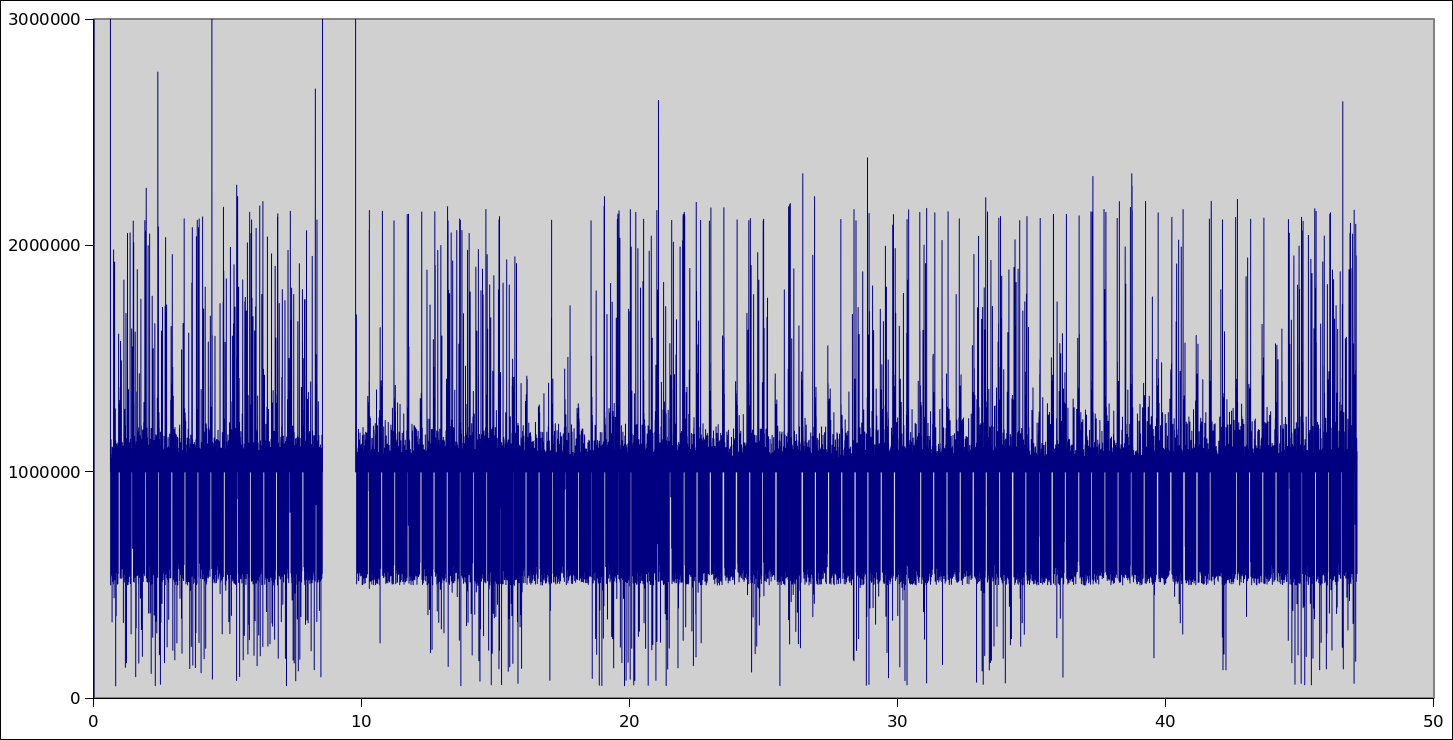
In this case, I wanted to generate a graph of how long the computer vision processing takes – from the moment each camera frame is captured until poses are generated for each device.
To do that, I have a some logging branches that output JSON events to log files and I write scripts to process those. I used that data and produced:
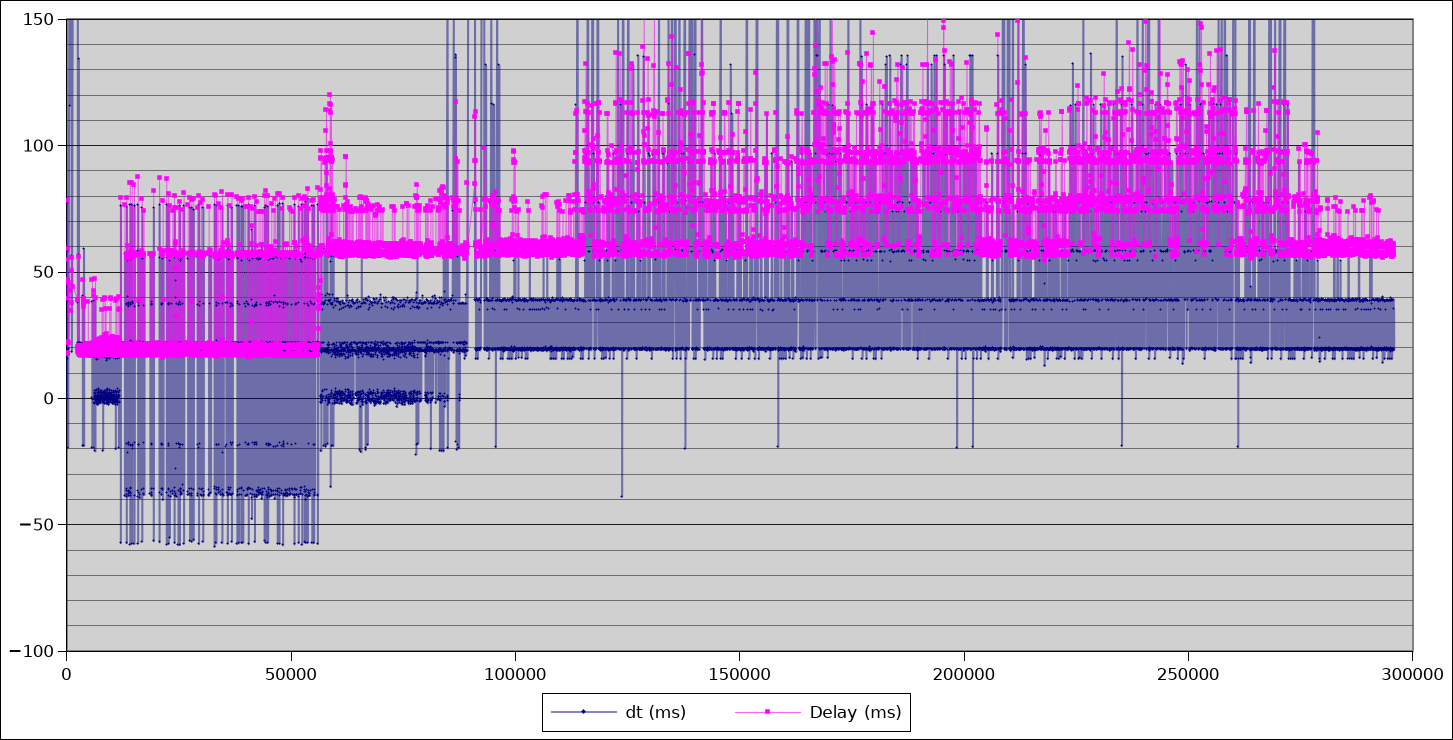
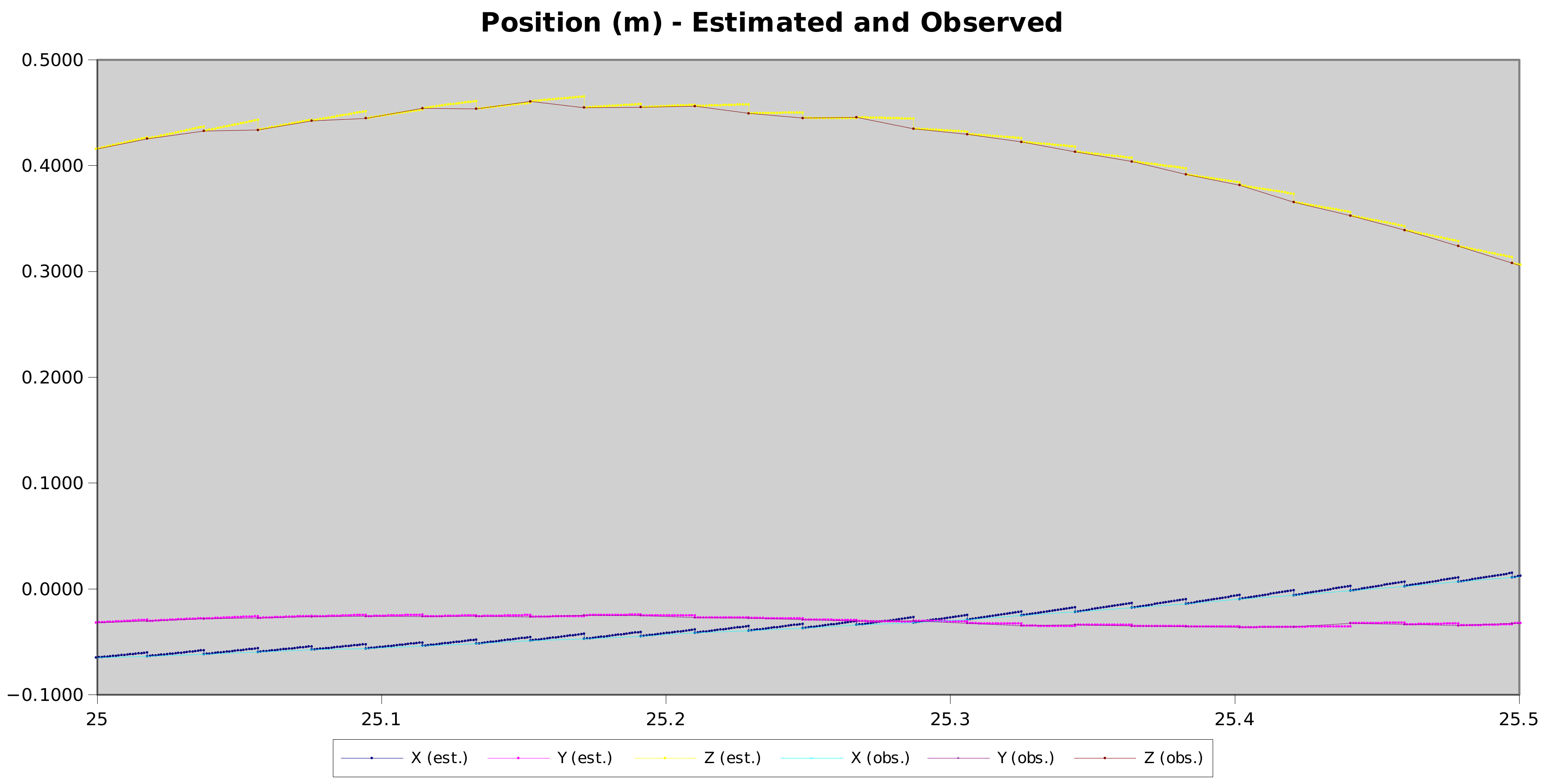
Two things caught my eye in this graph. The first is the way the baseline latency (pink lines) increases from ~20ms to ~58ms. The 2nd is the quantisation effect, where pose latencies are clearly moving in discrete steps.
Neither of those should be happening.
Camera frames are being captured from the CV1 sensors every 19.2ms, and it takes that 17-18ms for them to be delivered across the USB. Depending on how many IR sources the cameras can see, figuring out the device poses can take a different amount of time, but the baseline should always hover around 17-18ms because the fast “device tracking locked” case take as little as 1ms.
Did you see me mention 19.2ms as the interframe period? Guess what the spacing on those quantisation levels are in the graph? I recognised it as implying that something in the processing is tied to frame timing when it should not be.
OpenHMD Rift CV1 tracking timing
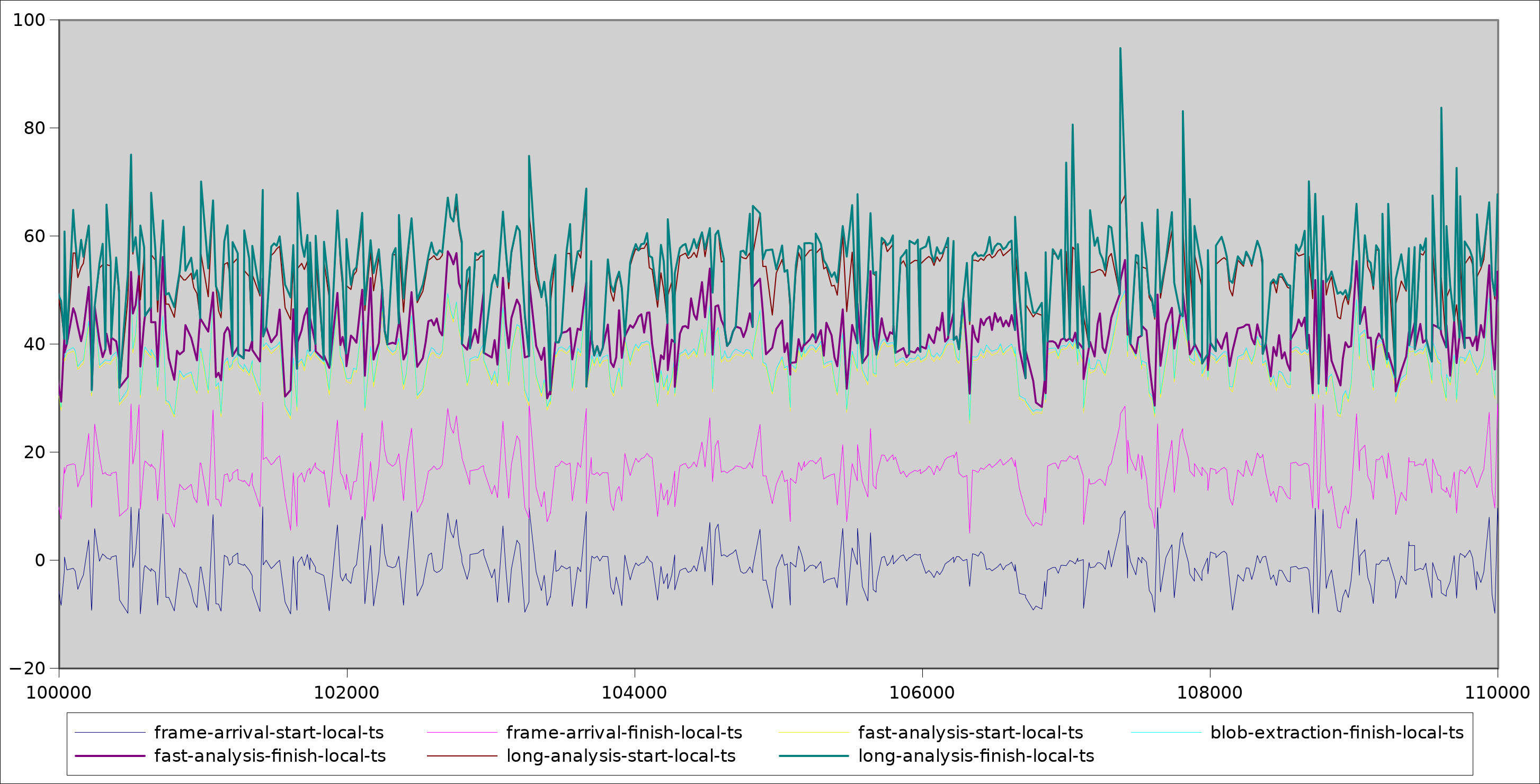
This 2nd graph helped me pinpoint what exactly was going on. This graph is cut from the part of the session where the latency has jumped up. What it shows is a ~1 frame delay between when the frame is received (frame-arrival-finish-local-ts) before the initial analysis even starts!
That could imply that the analysis thread is just busy processing the previous frame and doesn’t get start working on the new one yet – but the graph says that fast analysis is typically done in 1-10ms at most. It should rarely be busy when the next frame arrives.
This is where I found the bone headed code – a rookie mistake I wrote when putting in place the image analysis threads early on in the driver development and never noticed.
There are 3 threads involved:
USB service thread, reading video frame packets and assembling pixels in framebuffers
Fast analysis thread, that checks tracking lock is still acquired
Long analysis thread, which does brute-force pose searching to reacquire / match unknown IR sources to device LEDs
These 3 threads communicate using frame worker queues passing frames between each other. Each analysis thread does this pseudocode:
while driver_running:
Pop a frame from the queue
Process the frame
Sleep for new frame notification
The problem is in the 3rd line. If the driver is ever still processing the frame in line 2 when a new frame arrives – say because the computer got really busy – the thread sleeps anyway and won’t wake up until the next frame arrives. At that point, there’ll be 2 frames in the queue, but it only still processes one – so the analysis gains a 1 frame latency from that point on. If it happens a second time, it gets later by another frame! Any further and it starts reclaiming frames from the queues to keep the video capture thread fed – but it only reclaims one frame at a time, so the latency remains!
The fix is simple:
while driver_running:
Pop a frame
Process the frame
if queue_is_empty():
sleep for new frame notification
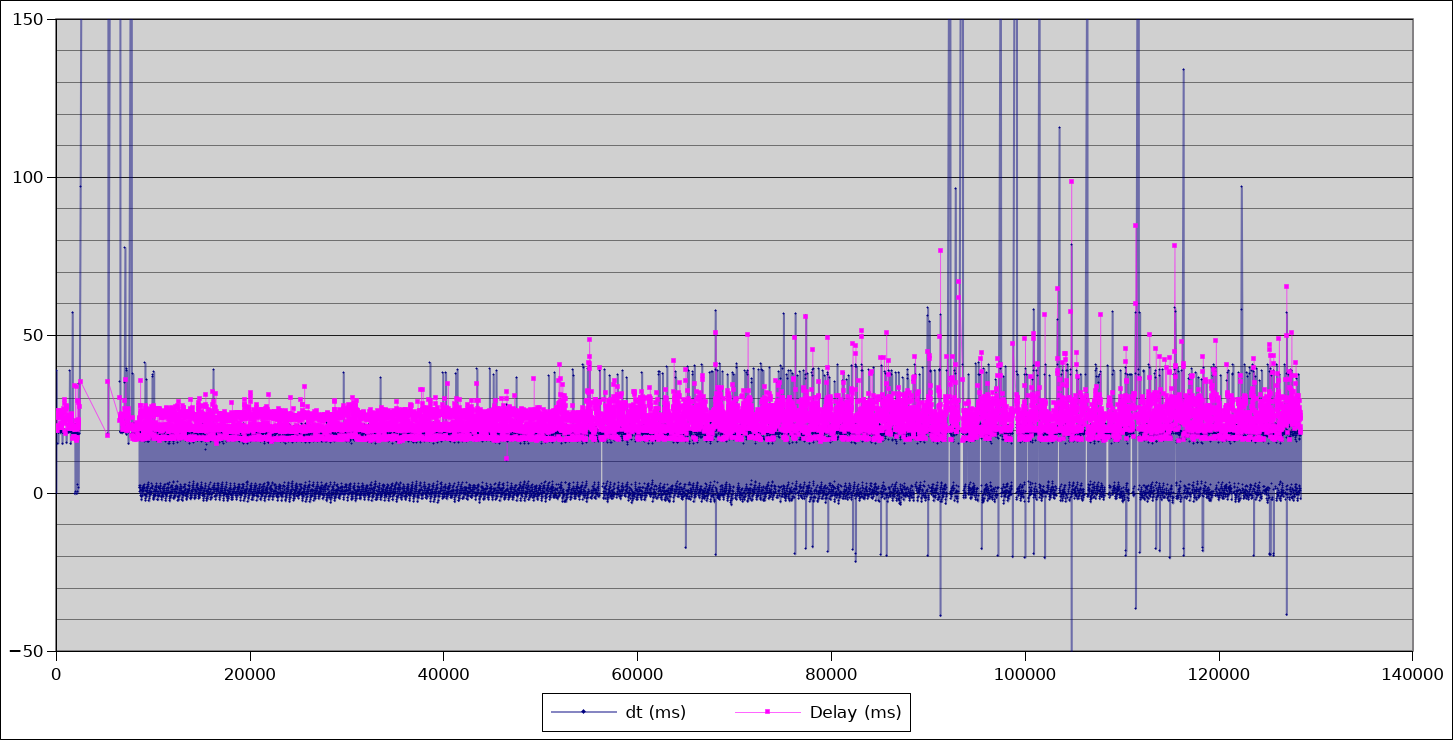
Doing that for both the fast and long analysis threads changed the profile of the pose latency graph completely.
Pose latency and inter-pose spacing after fix
This is a massive win! To be clear, this has been causing problems in the driver for at least 18 months but was never obvious from the logs alone. A single good graph is worth a thousand logs.
What does this mean in practice?
The way the fusion filter I’ve built works, in between pose updates from the cameras, the position and orientation of each device are predicted / updated using the accelerometer and gyro readings. Particularly for position, using the IMU for prediction drifts fairly quickly. The longer the driver spends ‘coasting’ on the IMU, the less accurate the position tracking is. So, the sooner the driver can get a correction from the camera to the fusion filter the less drift we’ll get – especially under fast motion. Particularly for the hand controllers that get waved around.
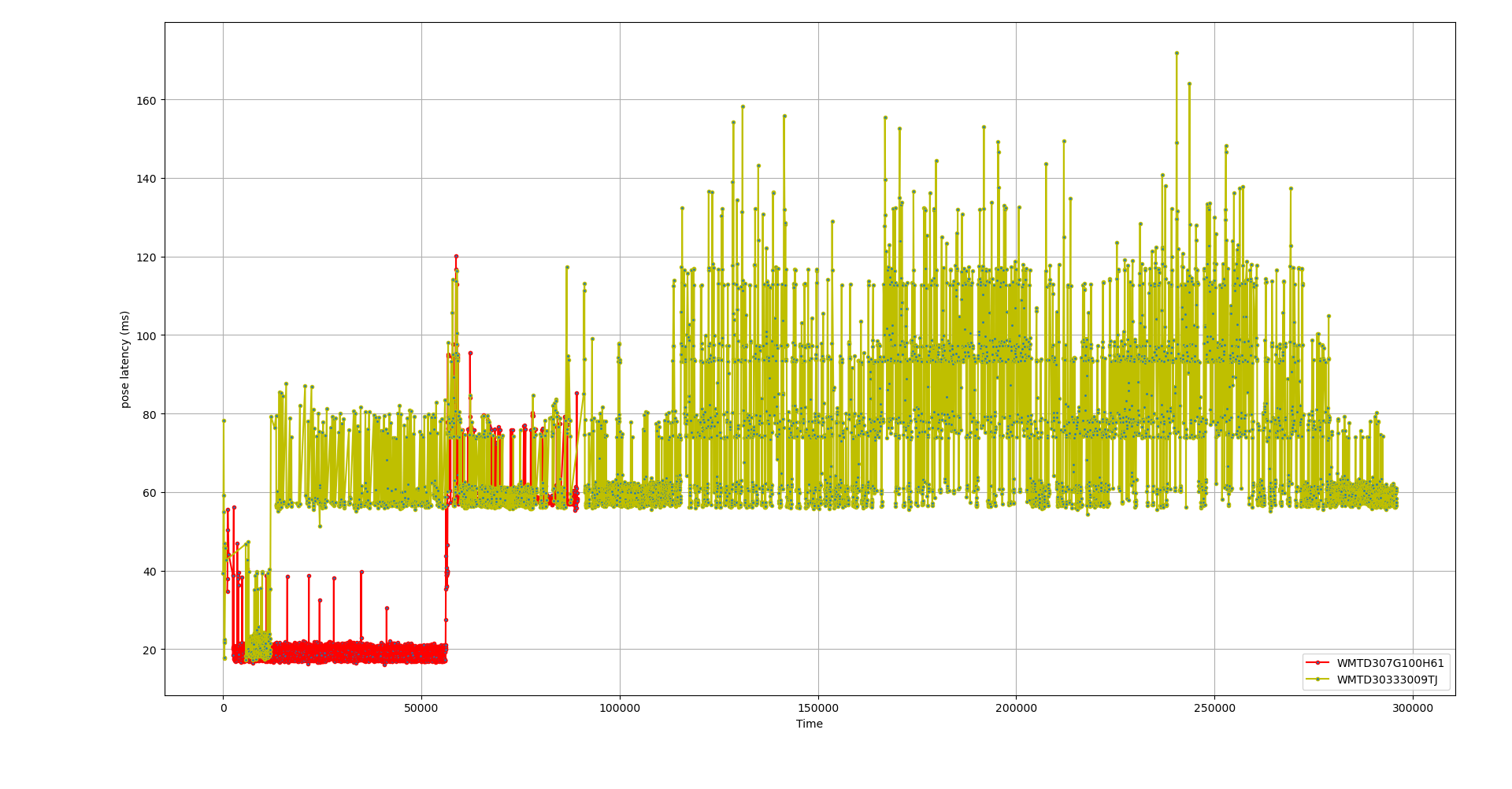
Before: Left Controller pose delays by sensorAfter: Left Controller pose delays by sensor
Poses are now being updated up to 40ms earlier and the baseline is consistent with the USB transfer delay.
You can also visibly see the effect of the JPEG decoding support I added over Christmas. The ‘red’ camera is directly connected to USB3, while the ‘khaki’ camera is feeding JPEG frames over USB2 that then need to be decoded, adding a few ms delay.
The latency reduction is nicely visible in the pose graphs, where the ‘drop shadow’ effect of pose updates tailing fusion predictions largely disappears and there are fewer large gaps in the pose observations when long analysis happens (visible as straight lines jumping from point to point in the trace):
Before: Left Controller posesAfter: Left Controller poses
Once again time has passed, and another update on Oculus Rift support feels due! As always, it feels like I’ve been busy with work and not found enough time for Rift CV1 hacking. Nevertheless, looking back over the history since I last wrote, there’s quite a lot to tell!
In general, the controller tracking is now really good most of the time. Like, wildly-swing-your-arms-and-not-lose-track levels (most of the time). The problems I’m hunting now are intermittent and hard to identify in the moment while using the headset – hence my enthusiasm over the last updates for implementing stream recording and a simulation setup. I’ll get back to that.
Outlier Detection
Since I last wrote, the tracking improvements have mostly come from identifying and rejecting incorrect measurements. That is, if I have 2 sensors active and 1 sensor says the left controller is in one place, but the 2nd sensor says it’s somewhere else, we’ll reject one of those – choosing the pose that best matches what we already know about the controller. The last known position, the gravity direction the IMU is detecting, and the last known orientation. The tracker will now also reject observations for a time if (for example) the reported orientation is outside the range we expect. The IMU gyroscope can track the orientation of a device for quite a while, so can be relied on to identify strong pose priors once we’ve integrated a few camera observations to get the yaw correct.
It works really well, but I think improving this area is still where most future refinements will come. That and avoiding incorrect pose extractions in the first place.
Plot of headset tracking – orientation and position
The above plot is a sample of headset tracking, showing the extracted poses from the computer vision vs the pose priors / tracking from the Kalman filter. As you can see, there are excursions in both position and orientation detected from the video, but these are largely ignored by the filter, producing a steadier result.
Left Touch controller tracking – orientation and position
This plot shows the left controller being tracked during a Beat Saber session. The controller tracking plot is quite different, because controllers move a lot more than the headset, and have fewer LEDs to track against. There are larger gaps here in the timeline while the vision re-acquires the device – and in those gaps you can see the Kalman filter interpolating using IMU input only (sometimes well, sometimes less so).
Improved Pose Priors
Another nice thing I did is changes in the way the search for a tracked device is made in a video frame. Before starting looking for a particular device it always now gets the latest estimate of the previous device position from the fusion filter. Previously, it would use the estimate of the device pose as it was when the camera exposure happened – but between then and the moment we start analysis more IMU observations and other camera observations might arrive and be integrated into the filter, which will have updated the estimate of where the device was in the frame.
This is the bit where I think the Kalman filter is particularly clever: Estimates of the device position at an earlier or later exposure can improve and refine the filter’s estimate of where the device was when the camera captured the frame we’re currently analysing! So clever. That mechanism (lagged state tracking) is what allows the filter to integrate past tracking observations once the analysis is done – so even if the video frame search take 150ms (for example), it will correct the filter’s estimate of where the device was 150ms in the past, which ripples through and corrects the estimate of where the device is now.
LED visibility model
To improve the identification of devices better, I measured the actual angle from which LEDs are visible (about 75 degrees off axis) and measured the size. The pose matching now has a better idea of which LEDs should be visible for a proposed orientation and what pixel size we expect them to have at a particular distance.
Better Smoothing
I fixed a bug in the output pose smoothing filter where it would glitch as you turned completely around and crossed the point where the angle jumps from +pi to -pi or vice versa.
Improved Display Distortion Correction
I got a wide-angle hi-res webcam and took photos of a checkerboard pattern through the lens of my headset, then used OpenCV and panotools to calculate new distortion and chromatic aberration parameters for the display. For me, this has greatly improved. I’m waiting to hear if that’s true for everyone, or if I’ve just fixed it for my headset.
Persistent Config Cache
Config blocks! A long time ago, I prototyped code to create a persistent OpenHMD configuration file store in ~/.config/openhmd. The rift-kalman-filter branch now uses that to store the configuration blocks that it reads from the controllers. The first time a controller is seen, it will load the JSON calibration block as before, but it will now store it in that directory – removing a multiple second radio read process on every subsequent startup.
Persistent Room Configuration
To go along with that, I have an experimental rift-room-config branch that creates a rift-room-config.json file and stores the camera positions after the first startup. I haven’t pushed that to the rift-kalman-filter branch yet, because I’m a bit worried it’ll cause surprising problems for people. If the initial estimate of the headset pose is wrong, the code will back-project the wrong positions for the cameras, which will get written to the file and cause every subsequent run of OpenHMD to generate bad tracking until the file is removed. The goal is to have a loop that monitors whether the camera positions seem stable based on the tracking reports, and to use averaging and resetting to correct them if not – or at least to warn the user that they should re-run some (non-existent) setup utility.
Video Capture + Processing
The final big ticket item was a rewrite of how the USB video frame capture thread collects pixels and passes them to the analysis threads. This now does less work in the USB thread, so misses fewer frames, and also I made it so that every frame is now searched for LEDs and blob identities tracked with motion vectors, even when no further analysis will be done on that frame. That means that when we’re running late, it better preserves LED blob identities until the analysis threads can catch up – increasing the chances of having known LEDs to directly find device positions and avoid searching. This rewrite also opened up a path to easily support JPEG decode – which is needed to support Rift Sensors connected on USB 2.0 ports.
Session Simulator
I mentioned the recording simulator continues to progress. Since the tracking problems are now getting really tricky to figure out, this tool is becoming increasingly important. So far, I have code in OpenHMD to record all video and tracking data to a .mkv file. Then, there’s a simulator tool that loads those recordings. Currently it is capable of extracting the data back out of the recording, parsing the JSON and decoding the video, and presenting it to a partially implemented simulator that then runs the same blob analysis and tracking OpenHMD does. The end goal is a Godot based visualiser for this simulation, and to be able to step back and forth through time examining what happened at critical moments so I can improve the tracking for those situations.
To make recordings, there’s the rift-debug-gstreamer-record branch of OpenHMD. If you have GStreamer and the right plugins (gst-plugins-good) installed, and you set env vars like this, each run of OpenHMD will generate a recording in the target directory (make sure the target dir exists):
The next things that are calling to me are to improve the room configuration estimation and storage as mentioned above – to detect when the poses a camera is reporting don’t make sense because it’s been bumped or moved.
I’d also like to add back in tracking of the LEDS on the back of the headset headband, to support 360 tracking. I disabled those because they cause me trouble – the headband is adjustable relative to the headset, so the LEDs don’t appear where the 3D model says they should be and that causes jitter and pose mismatches. They need special handling.
One last thing I’m finding exciting is a new person taking an interest in Rift S and starting to look at inside-out tracking for that. That’s just happened in the last few days, so not much to report yet – but I’ll be happy to have someone looking at that while I’m still busy over here in CV1 land!
As always, if you have any questions, comments or testing feedback – hit me up at thaytan@noraisin.net or on @thaytan Twitter/IRC.
Thank you to the kind people signed up as Github Sponsors for this project!
A while ago, I wrote a post about how to build and test my Oculus CV1 tracking code in SteamVR using the SteamVR-OpenHMD driver. I have updated those instructions and moved them to https://noraisin.net/diary/?page_id=1048 – so use those if you’d like to try things out.
The pandemic continues to sap my time for OpenHMD improvements. Since my last post, I have been working on various refinements. The biggest visible improvements are:
Adding velocity and acceleration API to OpenHMD.
Rewriting the pose transformation code that maps from the IMU-centric tracking space to the device pose needed by SteamVR / apps.
Adding velocity and acceleration reporting is needed in VR apps that support throwing things. It means that throwing objects and using gravity-grab to fetch objects works in Half-Life: Alyx, making it playable now.
The rewrite to the pose transformation code fixed problems where the rotation of controller models in VR didn’t match the rotation applied in the real world. Controllers would appear attached to the wrong part of the hand, and rotate around the wrong axis. Movements feel more natural now.
Ongoing work – record and replay
My focus going forward is on fixing glitches that are caused by tracking losses or outliers. Those problems happen when the computer vision code either fails to match what the cameras see to the device LED models, or when it matches incorrectly.
Tracking failure leads to the headset view or controllers ‘flying away’ suddenly. Incorrect matching leads to controllers jumping and jittering to the wrong pose, or swapping hands. Either condition is very annoying.
Unfortunately, as the tracking has improved the remaining problems get harder to understand and there is less low-hanging fruit for improvement. Further, when the computer vision runs at 52Hz, it’s impossible to diagnose the reasons for a glitch in real time.
I’ve built a branch of OpenHMD that uses GStreamer to record the CV1 camera video, plus IMU and tracking logs into a video file.
To go with those recordings, I’ve been working on a replay and simulation tool, that uses the Godot game engine to visualise the tracking session. The goal is to show, frame-by-frame, where OpenHMD thought the cameras, headset and controllers were at each point in the session, and to be able to step back and forth through the recording.
Right now, I’m working on the simulation portion of the replay, that will use the tracking logs to recreate all the poses.
It’s been a while since my last post about tracking support for the Oculus Rift in February. There’s been big improvements since then – working really well a lot of the time. It’s gone from “If I don’t make any sudden moves, I can finish an easy Beat Saber level” to “You can’t hide from me!” quality.
Equally, there are still enough glitches and corner cases that I think I’ll still be at this a while.
Here’s a video from 3 weeks ago of (not me) playing Beat Saber on Expert+ setting showing just how good things can be now:
Beat Saber – Skunkynator playing Expert+, Mar 16 2021
Strap in. Here’s what I’ve worked on in the last 6 weeks:
Pose Matching improvements
Most of the biggest improvements have come from improving the computer vision algorithm that’s matching the observed LEDs (blobs) in the camera frames to the 3D models of the devices.
I split the brute-force search algorithm into 2 phases. It now does a first pass looking for ‘obvious’ matches. In that pass, it does a shallow graph search of blobs and their nearest few neighbours against LEDs and their nearest neighbours, looking for a match using a “Strong” match metric. A match is considered strong if expected LEDs match observed blobs to within 1.5 pixels.
Coupled with checks on the expected orientation (matching the Gravity vector detected by the IMU) and the pose prior (expected position and orientation are within predicted error bounds) this short-circuit on the search is hit a lot of the time, and often completes within 1 frame duration.
In the remaining tricky cases, where a deeper graph search is required in order to recover the pose, the initial search reduces the number of LEDs and blobs under consideration, speeding up the remaining search.
I also added an LED size model to the mix – for a candidate pose, it tries to work out how large (in pixels) each LED should appear, and use that as a bound on matching blobs to LEDs. This helps reduce mismatches as devices move further from the camera.
LED labelling
When a brute-force search for pose recovery completes, the system now knows the identity of various blobs in the camera image. One way it avoids a search next time is to transfer the labels into future camera observations using optical-flow tracking on the visible blobs.
The problem is that even sped-up the search can still take a few frame-durations to complete. Previously LED labels would be transferred from frame to frame as they arrived, but there’s now a unique ID associated with each blob that allows the labels to be transferred even several frames later once their identity is known.
IMU Gyro scale
One of the problems with reverse engineering is the guesswork around exactly what different values mean. I was looking into why the controller movement felt “swimmy” under fast motions, and one thing I found was that the interpretation of the gyroscope readings from the IMU was incorrect.
The touch controllers report IMU angular velocity readings directly as a 16-bit signed integer. Previously the code would take the reading and divide by 1024 and use the value as radians/second.
From teardowns of the controller, I know the IMU is an Invensense MPU-6500. From the datasheet, the reported value is actually in degrees per second and appears to be configured for the +/- 2000 °/s range. That yields a calculation of Gyro-rad/s = Gyro-°/s * (2000 / 32768) * (?/180) – or a divisor of 938.734.
The 1024 divisor was under-estimating rotation speed by about 10% – close enough to work until you start moving quickly.
Limited interpolation
If we don’t find a device in the camera views, the fusion filter predicts motion using the IMU readings – but that quickly becomes inaccurate. In the worst case, the controllers fly off into the distance. To avoid that, I added a limit of 500ms for ‘coasting’. If we haven’t recovered the device pose by then, the position is frozen in place and only rotation is updated until the cameras find it again.
Exponential filtering
I implemented a 1-Euro exponential smoothing filter on the output poses for each device. This is an idea from the Project Esky driver for Project North Star/Deck-X AR headsets, and almost completely eliminates jitter in the headset view and hand controllers shown to the user. The tradeoff is against introducing lag when the user moves quickly – but there are some tunables in the exponential filter to play with for minimising that. For now I’ve picked some values that seem to work reasonably.
Non-blocking radio
Communications with the touch controllers happens through USB radio command packets sent to the headset. The main use of radio commands in OpenHMD is to read the JSON configuration block for each controller that is programmed in at the factory. The configuration block provides the 3D model of LED positions as well as initial IMU bias values.
Unfortunately, reading the configuration block takes a couple of seconds on startup, and blocks everything while it’s happening. Oculus saw that problem and added a checksum in the controller firmware. You can read the checksum first and if it hasn’t changed use a local cache of the configuration block. Eventually, I’ll implement that caching mechanism for OpenHMD but in the meantime it still reads the configuration blocks on each startup.
As an interim improvement I rewrote the radio communication logic to use a state machine that is checked in the update loop – allowing radio communications to be interleaved without blocking the regularly processing of events. It still interferes a bit, but no longer causes a full multi-second stall as each hand controller turns on.
Haptic feedback
The hand controllers have haptic feedback ‘rumble’ motors that really add to the immersiveness of VR by letting you sense collisions with objects. Until now, OpenHMD hasn’t had any support for applications to trigger haptic events. I spent a bit of time looking at USB packet traces with Philipp Zabel and we figured out the radio commands to turn the rumble motors on and off.
In the Rift CV1, the haptic motors have a mode where you schedule feedback events into a ringbuffer – effectively they operate like a low frequency audio device. However, that mode was removed for the Rift S (and presumably in the Quest devices) – and deprecated for the CV1.
With that in mind, I aimed for implementing the unbuffered mode, with explicit ‘motor on + frequency + amplitude’ and ‘motor off’ commands sent as needed. Thanks to already having rewritten the radio communications to use a state machine, adding haptic commands was fairly easy.
I’d say the biggest problem right now is unexpected tracking loss and incorrect pose extractions when I’m not expecting them. Especially my right controller will suddenly glitch and start jumping around. Looking at a video of the debug feed, it’s not obvious why that’s happening:
To fix cases like those, I plan to add code to log the raw video feed and the IMU information together so that I can replay the video analysis frame-by-frame and investigate glitches systematically. Those recordings will also work as a regression suite to test future changes.
Sensor fusion efficiency
The Kalman filter I have implemented works really nicely – it does the latency compensation, predicts motion and extracts sensor biases all in one place… but it has a big downside of being quite expensive in CPU. The Unscented Kalman Filter CPU cost grows at O(n^3) with the size of the state, and the state in this case is 43 dimensional – 22 base dimensions, and 7 per latency-compensation slot. Running 1000 updates per second for the HMD and 500 for each of the hand controllers adds up quickly.
At some point, I want to find a better / cheaper approach to the problem that still provides low-latency motion predictions for the user while still providing the same benefits around latency compensation and bias extraction.
Lens Distortion
To generate a convincing illusion of objects at a distance in a headset that’s only a few centimetres deep, VR headsets use some interesting optics. The LCD/OLED panels displaying the output get distorted heavily before they hit the users eyes. What the software generates needs to compensate by applying the right inverse distortion to the output video.
Everyone that tests the CV1 notices that the distortion is not quite correct. As you look around, the world warps and shifts annoyingly. Sooner or later that needs fixing. That’s done by taking photos of calibration patterns through the headset lenses and generating a distortion model.
Camera / USB failures
The camera feeds are captured using a custom user-space UVC driver implementation that knows how to set up the special synchronisation settings of the CV1 and DK2 cameras, and then repeatedly schedules isochronous USB packet transfers to receive the video.
Occasionally, some people experience failure to re-schedule those transfers. The kernel rejects them with an out-of-memory error failing to set aside DMA memory (even though it may have been running fine for quite some time). It’s not clear why that happens – but the end result at the moment is that the USB traffic for that camera dies completely and there’ll be no more tracking from that camera until the application is restarted.
Often once it starts happening, it will keep happening until the PC is rebooted and the kernel memory state is reset.
Occluded cases
Tracking generally works well when the cameras get a clear shot of each device, but there are cases like sighting down the barrel of a gun where we expect that the user will line up the controllers in front of one another, and in front of the headset. In that case, even though we probably have a good idea where each device is, it can be hard to figure out which LEDs belong to which device.
If we already have a good tracking lock on the devices, I think it should be possible to keep tracking even down to 1 or 2 LEDs being visible – but the pose assessment code will have to be aware that’s what is happening.
Upstreaming
April 14th marks 2 years since I first branched off OpenHMD master to start working on CV1 tracking. How hard can it be, I thought? I’ll knock this over in a few months.
Since then I’ve accumulated over 300 commits on top of OpenHMD master that eventually all need upstreaming in some way.
One thing people have expressed as a prerequisite for upstreaming is to try and remove the OpenCV dependency. The tracking relies on OpenCV to do camera distortion calculations, and for their PnP implementation. It should be possible to reimplement both of those directly in OpenHMD with a bit of work – possibly using the fast LambdaTwist P3P algorithm that Philipp Zabel wrote, that I’m already using for pose extraction in the brute-force search.
Others
I’ve picked the top issues to highlight here. https://github.com/thaytan/OpenHMD/issues has a list of all the other things that are still on the radar for fixing eventually.
Other Headsets
At some point soon, I plan to put a pin in the CV1 tracking and look at adapting it to more recent inside-out headsets like the Rift S and WMR headsets. I implemented 3DOF support for the Rift S last year, but getting to full positional tracking for that and other inside-out headsets means implementing a SLAM/VIO tracking algorithm to track the headset position.
Once the headset is tracking, the code I’m developing here for CV1 to find and track controllers will hopefully transfer across – the difference with inside-out tracking is that the cameras move around with the headset. Finding the controllers in the actual video feed should work much the same.
Sponsorship
This development happens mostly in my spare time and partly as open source contribution time at work at Centricular. I am accepting funding through Github Sponsorships to help me spend more time on it – I’d really like to keep helping Linux have top-notch support for VR/AR applications. Big thanks to the people that have helped get this far.
This post documented an older method of building SteamVR-OpenHMD. I moved them to a page here. That version will be kept up to date for any future changes, so go there.
I’ve had a few people ask how to test my OpenHMD development branch of Rift CV1 positional tracking in SteamVR. Here’s what I do:
It is important to configure in release mode, as the kalman filtering code is generally too slow for real-time in debug mode (it has to run 2000 times per second)
Please note – only Rift sensors on USB 3.0 ports will work right now. Supporting cameras on USB 2.0 requires someone implementing JPEG format streaming and decoding.
It can be helpful to test OpenHMD is working by running the simple example. Check that it’s finding camera sensors at startup, and that the position seems to change when you move the headset:
Calibrate your expectations for how well tracking is working right now! Hint: It’s very experimental 🙂
Start SteamVR. Hopefully it should detect your headset and the light(s) on your Rift Sensor(s) should power on.
Meson
I prefer the Meson build system here. There’s also a cmake build for SteamVR-OpenHMD you can use instead, but I haven’t tested it in a while and it sometimes breaks as I work on my development branch.
I spent some time this weekend implementing a couple of my ideas for improving the way the tracking code in OpenHMD filters and rejects (or accepts) possible poses when trying to match visible LEDs to the 3D models for each device.
In general, the tracking proceeds in several steps (in parallel for each of the 3 devices being tracked):
Do a brute-force search to match LEDs to 3D models, then (if matched)
Assign labels to each LED blob in the video frame saying what LED they are.
Send an update to the fusion filter about the position / orientation of the device
Then, as each video frame arrives:
Use motion flow between video frames to track the movement of each visible LED
Use the IMU + vision fusion filter to predict the position/orientation (pose) of each device, and calculate which LEDs are expected to be visible and where.
Try and match up and refine the poses using the predicted pose prior and labelled LEDs. In the best case, the LEDs are exactly where the fusion predicts they’ll be. More often, the orientation is mostly correct, but the position has drifted and needs correcting. In the worst case, we send the frame back to step 1 and do a brute-force search to reacquire an object.
The goal is to always assign the correct LEDs to the correct device (so you don’t end up with the right controller in your left hand), and to avoid going back to the expensive brute-force search to re-acquire devices as much as possible
What I’ve been working on this week is steps 1 and 3 – initial acquisition of correct poses, and fast validation / refinement of the pose in each video frame, and I’ve implemented two new strategies for that.
Gravity Vector matching
The first new strategy is to reject candidate poses that don’t closely match the known direction of gravity for each device. I had a previous implementation of that idea which turned out to be wrong, so I’ve re-worked it and it helps a lot with device acquisition.
The IMU accelerometer and gyro can usually tell us which way up the device is (roll and pitch) but not which way they are facing (yaw). The measure for ‘known gravity’ comes from the fusion Kalman filter covariance matrix – how certain the filter is about the orientation of the device. If that variance is small this new strategy is used to reject possible poses that don’t have the same idea of gravity (while permitting rotations around the Y axis), with the filter variance as a tolerance.
Partial tracking matches
The 2nd strategy is based around tracking with fewer LED correspondences once a tracking lock is acquired. Initial acquisition of the device pose relies on some heuristics for how many LEDs must match the 3D model. The general heuristic threshold I settled on for now is that 2/3rds of the expected LEDs must be visible to acquire a cold lock.
With the new strategy, if the pose prior has a good idea where the device is and which way it’s facing, it allows matching on far fewer LED correspondences. The idea is to keep tracking a device even down to just a couple of LEDs, and hope that more become visible soon.
While this definitely seems to help, I think the approach can use more work.
Status
With these two new approaches, tracking is improved but still quite erratic. Tracking of the headset itself is quite good now and for me rarely loses tracking lock. The controllers are better, but have a tendency to “fly off my hands” unexpectedly, especially after fast motions.
I have ideas for more tracking heuristics to implement, and I expect a continuous cycle of refinement on the existing strategies and new ones for some time to come.
For now, here’s a video of me playing Beat Saber using tonight’s code. The video shows the debug stream that OpenHMD can generate via Pipewire, showing the camera feed plus overlays of device predictions, LED device assignments and tracked device positions. Red is the headset, Green is the right controller, Blue is the left controller.
Initial tracking is completely wrong – I see some things to fix there. When the controllers go offline due to inactivity, the code keeps trying to match LEDs to them for example, and then there are some things wrong with how it’s relabelling LEDs when they get incorrect assignments.
After that, there are periods of good tracking with random tracking losses on the controllers – those show the problem cases to concentrate on.
I hit an important OpenHMD milestone tonight – I completed a Beat Saber level using my Oculus Rift CV1!
I’ve been continuing to work on integrating Kalman filtering into OpenHMD, and on improving the computer vision that matches and tracks device LEDs. While I suspect noone will be completing Expert levels just yet, it’s working well enough that I was able to play through a complete level of Beat Saber. For a long time this has been my mental benchmark for tracking performance, and I’m really happy 🙂
Check it out:
I should admit at this point that completing this level took me multiple attempts. The tracking still has quite a tendency to lose track of controllers, or to get them confused and swap hands suddenly.
I have a list of more things to work on. See you at the next update!
In the last post I had started implementing an Unscented Kalman Filter for position and orientation tracking in OpenHMD. Over the Christmas break, I continued that work.
A Quick Recap
When reading below, keep in mind that the goal of the filtering code I’m writing is to combine 2 sources of information for tracking the headset and controllers.
The first piece of information is acceleration and rotation data from the IMU on each device, and the second is observations of the device position and orientation from 1 or more camera sensors.
The IMU motion data drifts quickly (at least for position tracking) and can’t tell which way the device is facing (yaw, but can detect gravity and get pitch/roll).
The camera observations can tell exactly where each device is, but arrive at a much lower rate (52Hz vs 500/1000Hz) and can take a long time to process (hundreds of milliseconds) to analyse to acquire or re-acquire a lock on the tracked device(s).
The goal is to acquire tracking lock, then use the motion data to predict the motion closely enough that we always hit the ‘fast path’ of vision analysis. The key here is closely enough – the more closely the filter can track and predict the motion of devices between camera frames, the better.
Integration in OpenHMD
When I wrote the last post, I had the filter running as a standalone application, processing motion trace data collected by instrumenting a running OpenHMD app and moving my headset and controllers around. That’s a really good way to work, because it lets me run modifications on the same data set and see what changed.
However, the motion traces were captured using the current fusion/prediction code, which frequently loses tracking lock when the devices move – leading to big gaps in the camera observations and more interpolation for the filter.
By integrating the Kalman filter into OpenHMD, the predictions are improved leading to generally much better results. Here’s one trace of me moving the headset around reasonably vigourously with no tracking loss at all.
Headset motion capture trace
If it worked this well all the time, I’d be ecstatic! The predicted position matched the observed position closely enough for every frame for the computer vision to match poses and track perfectly. Unfortunately, this doesn’t happen every time yet, and definitely not with the controllers – although I think the latter largely comes down to the current computer vision having more troubler matching controller poses. They have fewer LEDs to match against compared to the headset, and the LEDs are generally more side-on to a front-facing camera.
Taking a closer look at a portion of that trace, the drift between camera frames when the position is interpolated using the IMU readings is clear.
Headset motion capture – zoomed in view
This is really good. Most of the time, the drift between frames is within 1-2mm. The computer vision can only match the pose of the devices to within a pixel or two – so the observed jitter can also come from the pose extraction, not the filtering.
The worst tracking is again on the Z axis – distance from the camera in this case. Again, that makes sense – with a single camera matching LED blobs, distance is the most uncertain part of the extracted pose.
Losing Track
The trace above is good – the computer vision spots the headset and then the filtering + computer vision track it at all times. That isn’t always the case – the prediction goes wrong, or the computer vision fails to match (it’s definitely still far from perfect). When that happens, it needs to do a full pose search to reacquire the device, and there’s a big gap until the next pose report is available.
That looks more like this
Headset motion capture trace with tracking errors
This trace has 2 kinds of errors – gaps in the observed position timeline during full pose searches and erroneous position reports where the computer vision matched things incorrectly.
Fixing the errors in position reports will require improving the computer vision algorithm and would fix most of the plot above. Outlier rejection is one approach to investigate on that front.
Latency Compensation
There is inherent delay involved in processing of the camera observations. Every 19.2ms, the headset emits a radio signal that triggers each camera to capture a frame. At the same time, the headset and controller IR LEDS light up brightly to create the light constellation being tracked. After the frame is captured, it is delivered over USB over the next 18ms or so and then submitted for vision analysis. In the fast case where we’re already tracking the device the computer vision is complete in a millisecond or so. In the slow case, it’s much longer.
Overall, that means that there’s at least a 20ms offset between when the devices are observed and when the position information is available for use. In the plot above, this delay is ignored and position reports are fed into the filter when they are available. In the worst case, that means the filter is being told where the headset was hundreds of milliseconds earlier.
To compensate for that delay, I implemented a mechanism in the filter where it keeps extra position and orientation entries in the state that can be used to retroactively apply the position observations.
The way that works is to make a prediction of the position and orientation of the device at the moment the camera frame is captured and copy that prediction into the extra state variable. After that, it continues integrating IMU data as it becomes available while keeping the auxilliary state constant.
When a the camera frame analysis is complete, that delayed measurement is matched against the stored position and orientation prediction in the state and the error used to correct the overall filter. The cool thing is that in the intervening time, the filter covariance matrix has been building up the right correction terms to adjust the current position and orientation.
Here’s a good example of the difference:
Before: Position filtering with no latency compensationAfter: Latency-compensated position reports
Notice how most of the disconnected segments have now slotted back into position in the timeline. The ones that haven’t can either be attributed to incorrect pose extraction in the compute vision, or to not having enough auxilliary state slots for all the concurrent frames.
At any given moment, there can be a camera frame being analysed, one arriving over USB, and one awaiting “long term” analysis. The filter needs to track an auxilliary state variable for each frame that we expect to get pose information from later, so I implemented a slot allocation system and multiple slots.
The downside is that each slot adds 6 variables (3 position and 3 orientation) to the covariance matrix on top of the 18 base variables. Because the covariance matrix is square, the size grows quadratically with new variables. 5 new slots means 30 new variables – leading to a 48 x 48 covariance matrix instead of 18 x 18. That is a 7-fold increase in the size of the matrix (48 x 48 = 2304 vs 18 x 18 = 324) and unfortunately about a 10x slow-down in the filter run-time.
At that point, even after some optimisation and vectorisation on the matrix operations, the filter can only run about 3x real-time, which is too slow. Using fewer slots is quicker, but allows for fewer outstanding frames. With 3 slots, the slow-down is only about 2x.
There are some other possible approaches to this problem:
Running the filtering delayed, only integrating IMU reports once the camera report is available. This has the disadvantage of not reporting the most up-to-date estimate of the user pose, which isn’t great for an interactive VR system.
Keeping around IMU reports and rewinding / replaying the filter for late camera observations. This limits the overall increase in filter CPU usage to double (since we at most replay every observation twice), but potentially with large bursts when hundreds of IMU readings need replaying.
It might be possible to only keep 2 “full” delayed measurement slots with both position and orientation, and to keep some position-only slots for others. The orientation of the headset tends to drift much more slowly than position does, so when there’s a big gap in the tracking it would be more important to be able to correct the position estimate. Orientation is likely to still be close to correct.
Further optimisation in the filter implementation. I was hoping to keep everything dependency-free, so the filter implementation uses my own naive 2D matrix code, which only implements the features needed for the filter. A more sophisticated matrix library might perform better – but it’s hard to say without doing some testing on that front.
Controllers
So far in this post, I’ve only talked about the headset tracking and not mentioned controllers. The controllers are considerably harder to track right now, but most of the blame for that is in the computer vision part. Each controller has fewer LEDs than the headset, fewer are visible at any given moment, and they often aren’t pointing at the camera front-on.
Oculus Camera view of headset and left controller.
This screenshot is a prime example. The controller is the cluster of lights at the top of the image, and the headset is lower left. The computer vision has gotten confused and thinks the controller is the ring of random blue crosses near the headset. It corrected itself a moment later, but those false readings make life very hard for the filtering.
Position tracking of left controller with lots of tracking loss.
Here’s a typical example of the controller tracking right now. There are some very promising portions of good tracking, but they are interspersed with bursts of tracking losses, and wild drifting from the computer vision giving wrong poses – leading to the filter predicting incorrect acceleration and hence cascaded tracking losses. Particularly (again) on the Z axis.
Timing Improvements
One of the problems I was looking at in my last post is variability in the arrival timing of the various USB streams (Headset reports, Controller reports, camera frames). I improved things in OpenHMD on that front, to use timestamps from the devices everywhere (removing USB timing jitter from the inter-sample time).
There are still potential problems in when IMU reports from controllers get updated in the filters vs the camera frames. That can be on the order of 2-4ms jitter. Time will tell how big a problem that will be – after the other bigger tracking problems are resolved.
Sponsorships
All the work that I’m doing implementing this positional tracking is a combination of my free time, hours contributed by my employer Centricular and contributions from people via Github Sponsorships. If you’d like to help me spend more hours on this and fewer on other paying work, I appreciate any contributions immensely!
Next Steps
The next things on my todo list are:
Integrate the delayed-observation processing into OpenHMD (at the moment it is only in my standalone simulator).
Improve the filter code structure – this is my first kalman filter and there are some implementation decisions I’d like to revisit.
Publish the UKF branch for other people to try.
Circle back to the computer vision and look at ways to improve the pose extraction and better reject outlying / erroneous poses, especially for the controllers.
Think more about how to best handle / schedule analysis of frames from multiple cameras. At the moment each camera operates as a separate entity, capturing frames and analysing them in threads without considering what is happening in other cameras. That means any camera that can’t see a particular device starts doing full pose searches – which might be unnecessary if another camera still has a good view of the device. Coordinating those analyses across cameras could yield better CPU consumption, and let the filter retain fewer delayed observation slots.
In my last post I wrote about changes in my OpenHMD positional tracking branch to split analysis of the tracking frames from the camera sensors across multiple threads. In the 2 months since then, the only real change in the repository was to add some filtering to the pose search that rejects bad poses by checking if they align with the gravity vector observed by the IMU. That is in itself a nice improvement, but there is other work I’ve been doing that isn’t published yet.
The remaining big challenge (I think) to a usable positional tracking solution is fusing together the motion information that comes from the inertial tracking sensors (IMU) in the devices (headset, controllers) with the observations that come from the camera sensors (video frames). There are some high level goals for that fusion, and lots of fiddly details about why it’s hard.
At the high level, the IMUs provide partial information about the motion of each device at a high rate, while the cameras provide observations about the actual position in the room – but at a lower rate, and with sometimes large delays.
In the Oculus CV1, the IMU provides Accelerometer and Gyroscope readings at 1000Hz (500Hz for controllers), and from those it’s possible to compute the orientation of the device relative to the Earth (but not the compass direction it’s facing), and also to integrate acceleration readings to get velocity and position – but the position tracking from an IMU is only useful in the short term (a few seconds) as it drifts rapidly due to that double integration.
The accelerometers measure (surprise) the acceleration of the device, but are always also sensing the Earth’s gravity field. If a device is at rest, it will ideally report 9.81 m/s2, give or take noise and bias errors. When the device is in motion, the acceleration measured is the sum of the gravity field, bias errors and actual linear acceleration. To interpolate the position with any accuracy at all, you need to separate those 3 components with tight tolerance.
That’s about the point where the position observations from the cameras come into play. You can use those snapshots of the device position to determine the real direction that the devices are facing, and to correct for any errors in the tracked position and device orientation from the IMU integration – by teasing out the bias errors and gravity offset.
The current code uses some simple hacks to do the positional tracking – using the existing OpenHMD 3DOF complementary filter to compute the orientation, and some hacks to update the position when a camera finds the pose of a device.
The simple hacks work surprisingly well when devices don’t move too fast. The reason is (as previously discussed) that the video analysis takes a variable amount of time – if we can predict where a device is with a high accuracy and maintain “tracking lock”, then the video analysis is fast and runs in a few milliseconds. If tracking lock is lost, then a full search is needed to recover the tracking, and that can take hundreds of milliseconds to complete… by which time the device has likely moved a long way and requires another full pose search, which takes hundreds of milliseconds..
So, the goal of my current development is to write a single unified fusion filter that combines IMU and camera observations to better track and predict the motion of devices between camera frames. Better motion prediction means hitting the ‘fast analysis’ path more often, which leads to more frequent corrections of the unknowns in the IMU data, and (circularly) better motion predictions.
To do that, I am working on an Unscented Kalman Filter that tracks the position, velocity, acceleration, orientation and IMU accelerometer and gyroscope biases – with promising initial results.
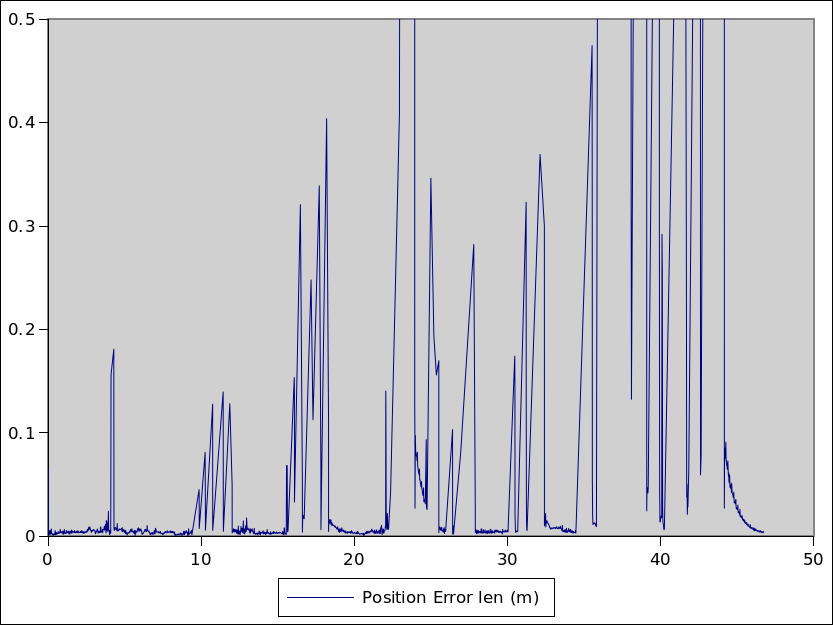
Graph of position error (m) between predicted position and position from camera observationsGraph of orientation error (degrees) between predicted orientation and camera observed pose.
In the above graphs, the filter is predicting the position of the headset at each camera frame to within 1cm most of the time and the pose to within a few degrees, but with some significant spikes that still need fixing. The explanation for the spikes lies in the data sets that I’m testing against, and points to the next work that needs doing.
To develop the filter, I’ve modifed OpenHMD to record traces as I move devices around. It saves out a JSON file for each device with a log of each IMU reading and each camera frame. The idea is to have a baseline data set that can be used to test each change in the filter – but there is a catch. The current data was captured using the upstream positional tracking code – complete with tracking losses and long analysis delays.
The spikes in the filter graph correspond with when the OpenHMD traces have big delays between when a camera frame was captured and when the analysis completes.
Delay (ms) between camera frame and analysis results.
What this means is that when the filter makes bad predictions, it’s because it’s trying to predict the position of the device at the time the sensor result became available, instead of when the camera frame was captured – hundreds of milliseconds earlier.
So, my next step is to integrate the Kalman filter code into OpenHMD itself, and hopefully capture a new set of motion data with fewer tracking losses to prove the filter’s accuracy more clearly.
Second – I need to extend the filter to compensate for that delay between when a camera frame is captured and when the results are available for use, by using an augmented state matrix and lagged covariances. More on that next time.
To finish up, here’s a taste of another challenge hidden in the data – variability in the arrival time of IMU updates. The IMU updates at 1000Hz – ideally we’d receive those IMU updates 1 per millisecond, but transfer across the USB and variability in scheduling on the host computer make that much noisier. Sometimes further apart, sometimes bunched together – and in one part there’s a 1.2 second gap.
This video shows the completion of work to split the tracking code into 3 threads – video capture, fast analysis and long analysis.
If the projected pose of an object doesn’t line up with the LEDs where we expect it to be, the frame is sent off for more expensive analysis in another thread. That way, it doesn’t block tracking of other objects – the fast analysis thread can continue with the next frame.
As a new blob is detected in a video frame, it is assigned an ID, and tracked between frames using motion flow. When the analysis results are available at some point in the future, the ID lets us find blobs that still exist in that most recent video frame. If the blobs are still unknowns in the new frame, the code labels them with the LED ID it found – and then hopefully in the next frame, the fast analysis is locked onto the object again.
There are some obvious next things to work on:
It’s hard to decide what constitutes a ‘good’ pose match, especially around partially visible LEDs at the edges. More experimentation and refinement needed
The IMU dead-reckoning between frames is bad – the accelerometer biases especially for the controllers tends to make them zoom off very quickly and lose tracking. More filtering, bias extraction and investigation should improve that, and help with staying locked onto fast-moving objects.
The code that decides whether an LED is expected to be visible in a given pose can use some improving.
Often the orientation of a device is good, but the position is wrong – a matching mode that only searches for translational matches could be good.
Taking the gravity vector of the device into account can help reject invalid poses, as could some tests against plausible location based on human movements limits.