In my last post I wrote about changes in my OpenHMD positional tracking branch to split analysis of the tracking frames from the camera sensors across multiple threads. In the 2 months since then, the only real change in the repository was to add some filtering to the pose search that rejects bad poses by checking if they align with the gravity vector observed by the IMU. That is in itself a nice improvement, but there is other work I’ve been doing that isn’t published yet.
The remaining big challenge (I think) to a usable positional tracking solution is fusing together the motion information that comes from the inertial tracking sensors (IMU) in the devices (headset, controllers) with the observations that come from the camera sensors (video frames). There are some high level goals for that fusion, and lots of fiddly details about why it’s hard.
At the high level, the IMUs provide partial information about the motion of each device at a high rate, while the cameras provide observations about the actual position in the room – but at a lower rate, and with sometimes large delays.
In the Oculus CV1, the IMU provides Accelerometer and Gyroscope readings at 1000Hz (500Hz for controllers), and from those it’s possible to compute the orientation of the device relative to the Earth (but not the compass direction it’s facing), and also to integrate acceleration readings to get velocity and position – but the position tracking from an IMU is only useful in the short term (a few seconds) as it drifts rapidly due to that double integration.
The accelerometers measure (surprise) the acceleration of the device, but are always also sensing the Earth’s gravity field. If a device is at rest, it will ideally report 9.81 m/s2, give or take noise and bias errors. When the device is in motion, the acceleration measured is the sum of the gravity field, bias errors and actual linear acceleration. To interpolate the position with any accuracy at all, you need to separate those 3 components with tight tolerance.
That’s about the point where the position observations from the cameras come into play. You can use those snapshots of the device position to determine the real direction that the devices are facing, and to correct for any errors in the tracked position and device orientation from the IMU integration – by teasing out the bias errors and gravity offset.
The current code uses some simple hacks to do the positional tracking – using the existing OpenHMD 3DOF complementary filter to compute the orientation, and some hacks to update the position when a camera finds the pose of a device.
The simple hacks work surprisingly well when devices don’t move too fast. The reason is (as previously discussed) that the video analysis takes a variable amount of time – if we can predict where a device is with a high accuracy and maintain “tracking lock”, then the video analysis is fast and runs in a few milliseconds. If tracking lock is lost, then a full search is needed to recover the tracking, and that can take hundreds of milliseconds to complete… by which time the device has likely moved a long way and requires another full pose search, which takes hundreds of milliseconds..
So, the goal of my current development is to write a single unified fusion filter that combines IMU and camera observations to better track and predict the motion of devices between camera frames. Better motion prediction means hitting the ‘fast analysis’ path more often, which leads to more frequent corrections of the unknowns in the IMU data, and (circularly) better motion predictions.
To do that, I am working on an Unscented Kalman Filter that tracks the position, velocity, acceleration, orientation and IMU accelerometer and gyroscope biases – with promising initial results.
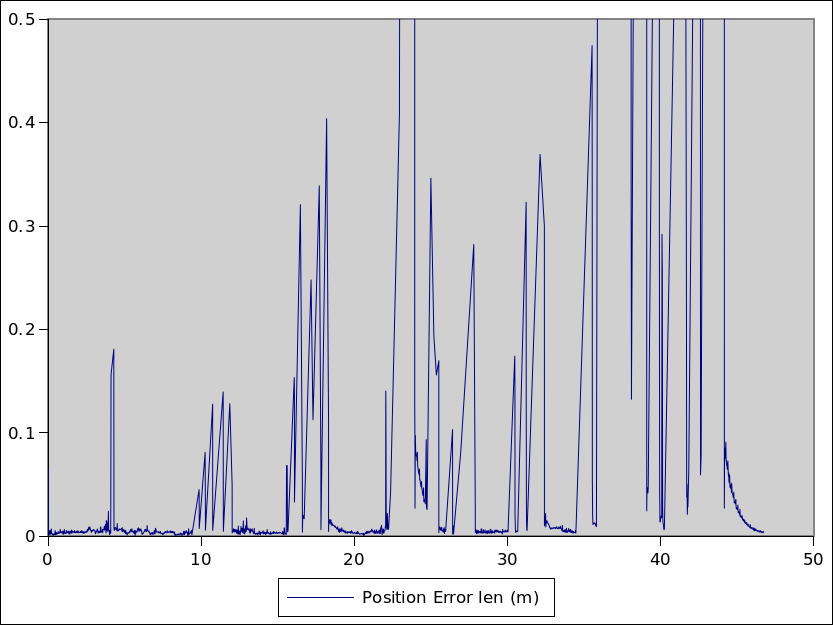
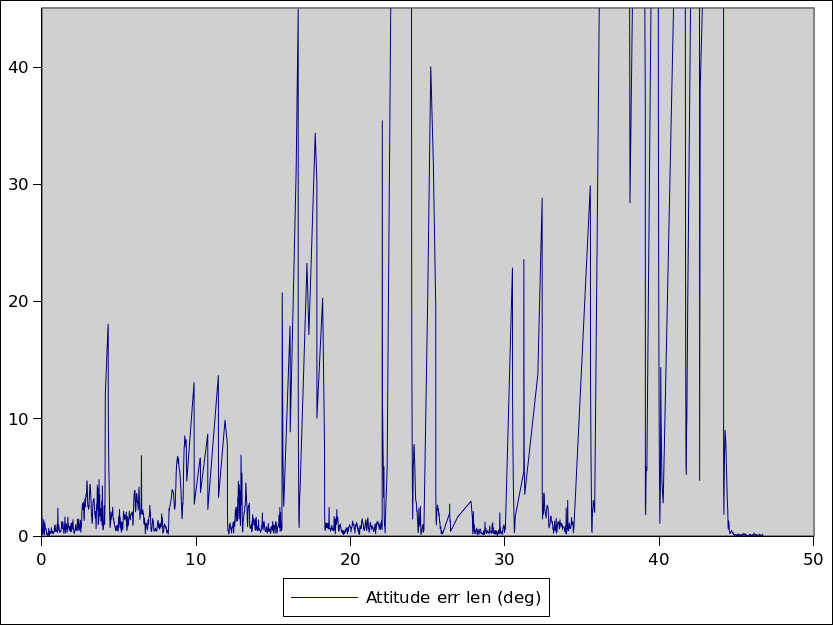
In the above graphs, the filter is predicting the position of the headset at each camera frame to within 1cm most of the time and the pose to within a few degrees, but with some significant spikes that still need fixing. The explanation for the spikes lies in the data sets that I’m testing against, and points to the next work that needs doing.
To develop the filter, I’ve modifed OpenHMD to record traces as I move devices around. It saves out a JSON file for each device with a log of each IMU reading and each camera frame. The idea is to have a baseline data set that can be used to test each change in the filter – but there is a catch. The current data was captured using the upstream positional tracking code – complete with tracking losses and long analysis delays.
The spikes in the filter graph correspond with when the OpenHMD traces have big delays between when a camera frame was captured and when the analysis completes.
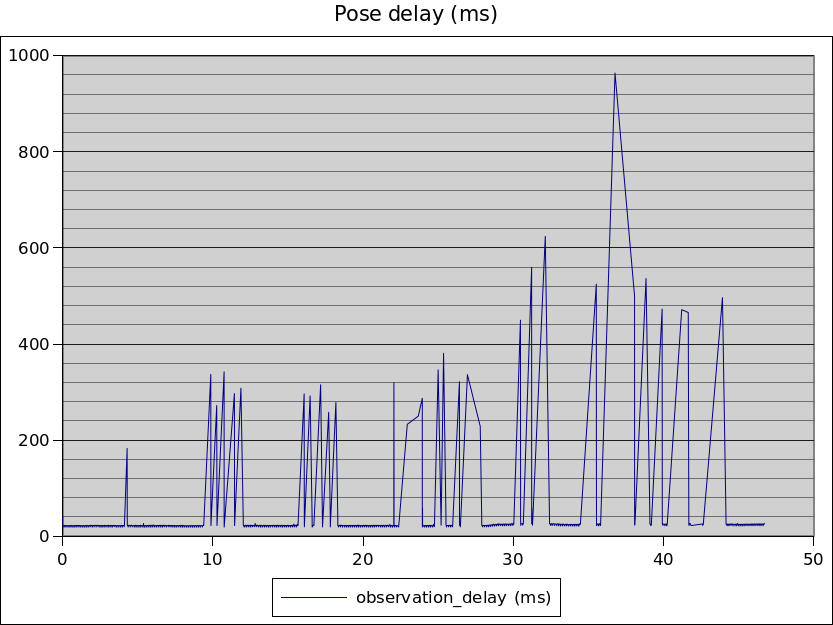
What this means is that when the filter makes bad predictions, it’s because it’s trying to predict the position of the device at the time the sensor result became available, instead of when the camera frame was captured – hundreds of milliseconds earlier.
So, my next step is to integrate the Kalman filter code into OpenHMD itself, and hopefully capture a new set of motion data with fewer tracking losses to prove the filter’s accuracy more clearly.
Second – I need to extend the filter to compensate for that delay between when a camera frame is captured and when the results are available for use, by using an augmented state matrix and lagged covariances. More on that next time.
To finish up, here’s a taste of another challenge hidden in the data – variability in the arrival time of IMU updates. The IMU updates at 1000Hz – ideally we’d receive those IMU updates 1 per millisecond, but transfer across the USB and variability in scheduling on the host computer make that much noisier. Sometimes further apart, sometimes bunched together – and in one part there’s a 1.2 second gap.